

Introduction
Recently I have had to think carefully about the nature of software systems, especially complex ones, and the bugs they contain. In doing so my thinking has been guided by certain beliefs I hold about complex software systems. These beliefs, or principles, are based on my practical experience but also on my studies, which, as well as teaching me much that I didn’t know, have helped me to make sense of what I have done and seen at work. Here are three vital principles I hold to be true.
Principle 1
Complex systems are not like calculators, which are predictable, deterministic instruments, i.e. they will always give the same answer from the same inputs. Complex systems are not predictable. We can only predict what they will probably do, but we cannot be certain. It is particularly important to remember this when working with complex socio-technical systems, i.e. complex systems, in the wider sense, that include humans, which are operated by people or require people to make them work. That covers most, or all, complex software systems.
Principle 2
Complex systems are more than the sum of their parts, or at least they are different. A system can be faulty even if all the individual programs,or components, are working correctly. The individual elements can combine with each other, and with the users, in unexpected and possibly damaging ways that could not have been predicted from inspecting the components separately.
Conversely, a system can be working satisfactorily even if some of the components are flawed. This inevitably means that the software code itself, however important it is, cannot be the only factor that determines the quality of the system.
Principle 3
Individual programs in a system can produce harmful outcomes even if their code was written perfectly. The outcome depends on how the different components, factors and people work together over the life of the system. Perfectly written code can cause a failure long after it has been released when there are changes to the technical, legal, or commercial environment in which the system runs.
The consequences
Bugs in complex systems are therefore inevitable. The absence of bugs in the past does not mean they are absent now, and certainly not that the system will be bug free in the future. The challenge is partly to find bugs, learn from them, and help users to learn how they can use the system safely. But testers should also try to anticipate future bugs, how they might arise, where the system is vulnerable, and learn how and whether users and operators will be able to detect problems and respond. They must then have the communication skills to explain what they have found to the people who need to know.
What we must not do is start off from the assumption that particular elements of the system are reliable and that any problems must have their roots elsewhere in the system. That mindset tends to push blame towards the unfortunate people who operate a flawed system.
Bugs and the Post Office Horizon scandal
 Over the last few months I have spent a lot of time on issues raised by the Post Office Horizon scandal. For a detailed account of the scandal I strongly recommend the supplement that Private Eye has produced, written by Richard Brooks and Nick Wallis, “Justice lost in the post”.
Over the last few months I have spent a lot of time on issues raised by the Post Office Horizon scandal. For a detailed account of the scandal I strongly recommend the supplement that Private Eye has produced, written by Richard Brooks and Nick Wallis, “Justice lost in the post”.
When I have been researching this affair I have realised, time and again, how the Post Office and Fujitsu, the outsourced IT services supplier, ignored the three principles I outlined. While trawling through the judgment of Mr Justice Fraser in Bates v Post Office Ltd (No 6: Horizon Issues, i.e. the second of the two court cases brought by the Justice For Subpostmasters Alliance), which should be compulsory reading for Computer Science students, I was struck by the judge’s discussion of the nature of bugs in computer systems. You can find the full 313 page judgment here [PDF, opens in new tab].
The definition of a bug was at the heart of the second court case. The Post Office, and Fujitsu (the outsourced IT services supplier) argued that a bug is a coding error, and the word should not apply to other problems. The counsel for the claimants, i.e. the subpostmasters and subpostmistresses who had been victims of the flawed system, took a broader view; a bug is anything that means the software does not operate as users, or the corporation, expect.
After listening to both sides Fraser came down emphatically on the claimants’ side.
“26 The phrase ‘bugs, errors or defects’ is sufficiently wide to capture the many different faults or characteristics by which a computer system might not work correctly… Computer professionals will often refer simply to ‘code’, and a software bug can refer to errors within a system’s source code, but ‘software bugs’ has become more of a general term and is not restricted, in my judgment, to meaning an error or defect specifically within source code, or even code in an operating system.
Source code is not the only type of software used in a system, particularly in a complex system such as Horizon which uses numerous applications or programmes too. Reference data is part of the software of most modern systems, and this can be changed without the underlying code necessarily being changed. Indeed, that is one of the attractions of reference data. Software bug means something within a system that causes it to cause an incorrect or unexpected result. During Mr de Garr Robinson’s cross-examination of Mr Roll, he concentrated on ‘code’ very specifically and carefully [de Garr Robinson was the lawyer representing the Post Office and Roll was a witness for the claimants who gave evidence about problems with Horizon that he had seen when he worked for Fujitsu]. There is more to the criticisms levelled at Horizon by the claimants than complaints merely about bugs within the Horizon source code.
27 Bugs, errors or defects is not a phrase restricted solely to something contained in the source code, or any code. It includes, for example, data errors, data packet errors, data corruption, duplication of entries, errors in reference data and/or the operation of the system, as well as a very wide type of different problems or defects within the system. ‘Bugs, errors or defects’ is wide enough wording to include a wide range of alleged problems with the system.”
The determination of the Post Office and Fujitsu to limit the definition of bugs to source code was part of a policy of blaming users for all errors that were not obviously caused by the source code. This is clear from repeated comments from witnesses and from Mr Justice Fraser in the judgment. “User error” was the default explanation for all problems.
Phantom transactions or bugs?
This stance of blaming the users if they were confused by Horizon’s design was taken to an extreme with “phantom transactions”. These were transactions generated by the system but which were recorded as if they had been made by a user (see in particular paragraphs 209 to 214 of Fraser’s judgment).
In paragraph 212 Fraser refers to a Fujitsu problem report.
“However, the conclusion reached by Fujitsu and recorded in the PEAK was as follows:
‘Phantom transactions have not been proven in circumstances which preclude user error. In all cases where these have occurred a user error related cause can be attributed to the phenomenon.'”
This is striking. These phantom transactions had been observed by Royal Mail engineers. They were known to exist. But they were dismissed as a cause of problems unless it could be proven that user error was not responsible. If Fujitsu could imagine a scenario where user error might have been responsible for a problem they would rule out the possibility that a phantom transaction could have been the cause, even if the phantom had occurred. The PEAK (error report) would simply be closed off, whether or not the subpostmaster agreed.
This culture of blaming users rather than software was illustrated by a case of the system “working as designed” when its behaviour clearly confused and misled users. In fact the system was acting contrary to user commands. In certain circumstances if a user entered the details for a transaction, but did not commit it, the system would automatically complete the transaction with no further user intervention, which might result in a loss to the subpostmaster.
The Post Office, in a witness statement, described this as a “design quirk”. However, the Post Office’s barrister, Mr de Garr Robinson, in his cross-examination of Jason Coyne, an IT consultant hired by the subpostmasters, was able to convince Nick Wallis (one of the authors of “Justice lost in the post”) that there wasn’t a bug.
“Mr de Garr Robinson directs Mr Coyne to Angela van den Bogerd’s witness statement which notes this is a design quirk of Horizon. If a bunch of products sit in a basket for long enough on the screen Horizon will turn them into a sale automatically.
‘So this isn’t evidence of Horizon going wrong, is it?’ asks Mr de Garr Robinson. ‘It is an example of Horizon doing what it was supposed to do.’
‘It is evidence of the system doing something without the user choosing to do it.’ retorts Mr Coyne.
But that is not the point. It is not a bug in the system.”
Not a bug? I would contest that very strongly. If I were auditing a system with this “quirk” I would want to establish the reasons for the system’s behaviour. Was this feature deliberately designed into the system? Or was it an accidental by-product of the system design? Whatever the answer, it would be simply the start of a more detailed scrutiny of technical explanations, understanding of the nature of bugs, the reasons for a two-stage committal of data, and the reasons why those two stages were not always applied. I would not consider “working as designed” to be an acceptable answer.
The Post Office’s failure to grasp the nature of complex systems
A further revealing illustration of the Post Office’s attitude towards user error came in a witness statement provided for the Common Issues trial, the first of the two court cases brought by the Justice For Subpostmasters Alliance. This first trial was about the contractual relationship between the Post Office and subpostmasters. The statement came from Angela van den Bogerd. At the time she was People Services Director for the Post Office, but over the previous couple of decades she had been in senior technical positions, responsible for Horizon and its deployment. She described herself in court as “not an IT expert”. That is an interesting statement to consider alongside some of the comments in her witness statement.
“[78]… the Subpostmaster has complete control over the branch accounts and transactions only enter the branch accounts with the Subpostmaster’s (or his assistant’s) knowledge.
[92] I describe Horizon to new users as a big calculator. I think this captures the essence of the system in that it records the transactions inputted into it, and then adds or subtracts from the branch cash or stock holdings depending on whether it was a credit or debit transaction.”
“Complete control”? That confirms her admission that she is not an IT expert. I would never have been bold, or reckless, enough to claim that I was in complete control of any complex IT system for which I was responsible. The better I understood the system the less inclined I would be to make such a claim. Likening Horizon to a calculator is particularly revealing. See Principle 1 above. When I have tried to explain the nature of complex systems I have also used the calculator analogy, but as an illustration of what a complex system is not.
If a senior manager responsible for Horizon could use such a fundamentally mistaken analogy, and be prepared to insert it in a witness statement for a court case, it reveals how poorly equipped the Post Office management was to deal with the issues raised by Horizon. When we are confronted by complexity it is a natural reaction to try and construct a mental model that simplifies the problems and makes them understandable. This can be helpful. Indeed it is often essential if we are too make any sense of complexity. I have written about this here in my blog series “Dragons of the unknown”.
However, even the best models become dangerous if we lose sight of their limitations and start to think that they are exact representations of reality. They are no longer fallible aids to understanding, but become deeply deceptive.
If you think a computer system is like a calculator then you will approach problems with the wrong attitude. Calculators are completely reliable. Errors are invariably the result of users’ mistakes, “finger trouble”. That is exactly how senior Post Office managers, like Angela van den Bogerd, regarded the Horizon problems.
BugsZero
The Horizon scandal has implications for the argument that software developers can produce systems that have no bugs, that zero bugs is an attainable target. Arlo Belshee is a prominent exponent of this idea, of BugsZero as it is called. Here is a short introduction.
Before discussing anyone’s approach to bugs it is essential that we are clear what they mean by a bug. Belshee has a useful definition, which he provided in this talk in Singapore in 2016. (The conference website has a useful introduction to the talk.)
3:50 “The definition (of a bug) I use is anything that would frustrate, confuse or annoy a human and is potentially visible to a human other than the person who is currently actively writing (code).”
This definition is close to Justice Fraser’s (see above); “a bug is anything that means the software does not operate as users, or the corporation, expect”. However, I think that both definitions are limited.
BugsZero is a big topic, and I don’t have the time or expertise to do it justice, but for the purposes of this blog I’m happy to concede that it is possible for good coders to deliver exactly what they intend to, so that the code itself, within a particular program, will not act in ways that will “frustrate, confuse or annoy a human”, or at least a human who can detect the problem. That is the limitation of the definition. Not all faults with complex software will be detected. Some are not even detectable. Our inability to see them does not mean they are absent. Bugs can produce incorrect but plausible answers to calculations, or they can corrupt data, without users being able to see that a problem exists.
I speak from experience here. It might even be impossible for technical system experts to identify errors with confidence. It is not always possible to know whether a complex system is accurate. The insurance finance systems I used to work on were notoriously difficult to understand and manipulate. 100% accuracy was never a serious, practicable goal. As I wrote in “Fix on failure – a failure to understand failure”;
“With complex financial applications an honest and constructive answer to the question ‘is the application correct?’ would be some variant on ‘what do you mean by correct?’, or ‘I don’t know. It depends’. It might be possible to say the application is definitely not correct if it is producing obvious garbage. But the real difficulty is distinguishing between the seriously inaccurate, but plausible, and the acceptably inaccurate that is good enough to be useful. Discussion of accuracy requires understanding of critical assumptions, acceptable margins of error, confidence levels, the nature and availability of oracles, and the business context of the application.”
It is therefore misleading to define bugs as being potentially visible to users. Nevertheless, Belshee’s definition is useful provided that that qualification is accepted. However, in the same talk, Belshee goes on to make further statements I do not accept.
19:55 “A bug is an encoded developer mistake.”
28:50 “A bug is a mistake by a developer.”
This is a developer-centric view of systems. It is understandable if developers focus on the bugs for which they are responsible. However, if you look at the systems, and bugs, from the other end, from the perspective of users when a bug has resulted in frustration, confusion or annoyance, the responsibility for the problem is irrelevant. The disappointed human is uninterested in whether the problem is with the coding, the design, the interaction of programs or components, or whatever. All that matters is that the system is buggy.
There is a further complication. The coder may well have delivered code that was perfect when it was written and released. But perfect code can create later problems if the world in which it operates changes. See Principle 3 above. This aspect of software is not sufficiently appreciated; it has caused me a great deal of trouble in my career (see the section “Across time, not just at a point in time” in this blog, about working with Big Data).
Belshee does say that developers should take responsibility for bugs that manifest themselves elswhere, even if their code was written correctly. He also makes it clear, when talking about fault tolerant systems (17:22 in the talk above), that faults can arise “when the behaviour of the world is not as we expect”.
However he also says that the system “needs to work exactly as the developer thought if it’s going to recover”. That’s too high a bar for complex socio-technical systems. The most anyone can say, and it’s an ambitious target, is that the programs have been developed exactly as the developers intended. Belshee is correct at the program level; if the programs were not built as the developers intended then recovery will be very much harder. But at the system level we need to be clear and outspoken about the limits of what we can know, and about the inevitability that bugs are present.
If we start to raise hopes that systems might be perfect and bug-free because we believe that we can deliver perfectly written code then we are setting ourselves up for unpleasant recriminations when our users suffer from bugs. It is certainly laudable to eradicate sloppy and cavalier coding and it might be noble for developers to be willing to assume responsibility for all bugs. But it could leave them exposed to legal recriminations if the wider world believes that software developers can and should` ensure systems are free of bugs. This is where lawyers might become involved and that is why I’m unhappy about the name BugsZero, and the undeliverable promise that it implies.
Unnoticed and undetectable bugs in the Horizon case
The reality that a bug might be real and damaging but not detected by users, or even detectable by them, was discussed in the Horizon case.
“[972] Did the Horizon IT system itself alert Subpostmasters of such bugs, errors or defects… and if so how?
[973] Answer: Although the experts were agreed that the extent to which any IT system can automatically alert its users to bugs within the system itself is necessarily limited, and although Horizon has automated checks which would detect certain bugs, they were also agreed that there are types of bugs which would not be detected by such checks. Indeed, the evidence showed that some bugs lay undiscovered in the Horizon system for years. This issue is very easy, therefore, to answer. The correct answer is very short. The answer… is ‘No, the Horizon system did not alert SPMs’. The second part of the issue does not therefore arise.”
That is a significant extract from an important judgment. A senior judge directly addressed the question of system reliability and pronounced that he is satisfied that a complex system cannot be expected to have adequate controls to warn users of all errors.
This is more than an abstract, philosophical debate about proof, evidence and what we can know. In England there is a legal presumption that computer evidence is reliable. This made a significant contribution to the Horizon scandal. Both parties in a court case are obliged to disclose documents which might either support or undermine their case, so that the other side has a chance to inspect and challenge them. The Post Office and Fujitsu did not disclose anything that would have cast doubt on their computer evidence. That failure to disclose meant it was impossible for the subpostmasters being prosecuted to challenge the presumption that the evidence was reliable. The subpostmasters didn’t know about the relevant system problems, and they didn’t even know that that knowledge had been withheld from them.
Replacing the presumption of computer reliability
There are two broad approaches that can be taken in response to the presumption that computer evidence is reliable and the ease with which it can be abused, apart of course from ignoring the problem and accepting that injustice is a price worth paying for judicial convenience. England can scrap the presumption, which would require the party seeking to use the evidence to justify its reliability. Or the rules over disclosure can be strengthened to try and ensure that all relevant information about systems is revealed. Some blend of the two approaches seems most likely.
I have recently contributed to a paper entitled “Recommendations for the probity of computer evidence”. It has been submitted to the Ministry of Justice, which is responsible for the courts in England & Wales, and is available from the Digital Evidence and Electronic Signature Law Review.
The paper argues that the presumption of computer reliability should be replaced by a two stage approach when reliability is challenged. The provider of the data should first be required to provide evidence to demonstrate that they are in control of their systems, that they record and track all bugs, fixes, changes and releases, and that they have implemented appropriate security standards and processes.
If the party wishing to rely on the computer evidence cannot provide a satisfactory response in this first stage then the presumption of reliability should be reversed. The second stage would require them to prove that none of the failings revealed in the first stage might affect the reliability of the computer evidence.
Whatever approach is taken, IT professionals would have to offer an opinion on their systems. How reliable are the systems? What relevant evidence might there be that systems are reliable, or unreliable? Can they demonstrate that they are in control of their systems? Can they reassure senior managers who will have to put their name to a legal document and will be very keen to avoid the humiliation that has been heaped upon Post Office and Fujitsu executives, with the possibility of worse to come?
A challenging future
The extent to which we can rely on computers poses uncomfortable challenges for the English law now, but it will be an increasingly difficult problem for the IT world over the coming years. What can we reasonably say about the systems we work with? How reliable are they? What do we know about the bugs? Are we sufficiently clear about the nature of our systems to brief managers who will have to appear in court, or certify legal documents?
It will be essential that developers and testers are clear in their own minds, and in their communications, about what bugs are. They are not just coding errors, and we must try to ensure people outside IT understand that. Testers must also be able to communicate clearly what they have learned about systems, and they must never say or do anything that suggests systems will be free of bugs.
Testers will have to think carefully about the quality of their evidence, not just about the quality of their systems. How good is our evidence? How far can go in making confident statements of certainty? What do we still not know, and what is the significance of that missing knowledge? Much of this will be a question of good management. But organisations will need good testers, very good testers, who can explain what we know, and what we don’t know, about complex systems; testers who have the breadth of knowledge, the insight, and the communication skills to tell a convincing story to those who require the unvarnished truth.
We will need confident, articulate testers who can explain that a lack of certainty about how complex systems will behave is an honest, clear sighted, statement of truth. It is not an admission of weakness or incompetence. Too many people in IT have built good careers on bullshitting, on pretending they are more confident and certain than they have any right to be. Systems will inevitably become more complex. IT people will increasingly be dragged into litigation, and as the Post Office and Fujitsu executives have found, misplaced and misleading confidence and bluster in court have excruciating personal consequences. Unpleasant though these consequences are, they hardly compare with the tragedies endured by the subpostmasters and subpostmistresses, whose lives were ruined by corporations who insisted that their complex software was reliable.
The future might be difficult, even stressful, for software testers, but they will have a valuable, essential role to play in helping organisations and users to gain a better understanding of the fallible nature of software. To say the future will be interesting is an understatement; it will present exciting challenges and there should be great opportunities for the best testers.
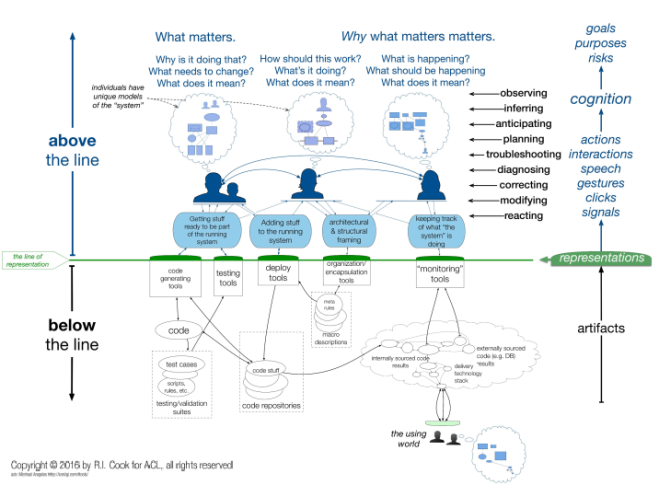
 The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in
The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in 


 Safety critical professionals have become closely involved in the field of resilience engineering. Dave Snowden, Cynefin’s creator, places great emphasis on the need for systems in complex environments to be resilient.
Safety critical professionals have become closely involved in the field of resilience engineering. Dave Snowden, Cynefin’s creator, places great emphasis on the need for systems in complex environments to be resilient.



 Safety I assumed linear cause and effect with root causes (see
Safety I assumed linear cause and effect with root causes (see  If Safety I wants to prevent bad outcomes, in contrast Safety II looks at how good outcomes are reached. Safety II is rooted in a more realistic understand of complex systems than Safety I and extends the focus to what goes right in systems. That entails a detailed examination of what people are doing with the system in the real world to keep it running. Instead of people being regarded as a weakness and a source of danger, Safety II assumes that people, and the adaptations they introduce to systems and processes, are the very reasons we usually get good, safe outcomes.
If Safety I wants to prevent bad outcomes, in contrast Safety II looks at how good outcomes are reached. Safety II is rooted in a more realistic understand of complex systems than Safety I and extends the focus to what goes right in systems. That entails a detailed examination of what people are doing with the system in the real world to keep it running. Instead of people being regarded as a weakness and a source of danger, Safety II assumes that people, and the adaptations they introduce to systems and processes, are the very reasons we usually get good, safe outcomes. As an example, an airline might offer a punctuality bonus to staff. For an airline safety obviously has the highest priority, but if it was an absolute priority, the only consideration, then it could not contemplate any incentive that would encourage crews to speed up turnarounds on the ground, or to persevere with a landing when prudence would dictate a “go around”. In truth, if safety were an absolute priority, with no element of risk being tolerated, would planes ever take off?
As an example, an airline might offer a punctuality bonus to staff. For an airline safety obviously has the highest priority, but if it was an absolute priority, the only consideration, then it could not contemplate any incentive that would encourage crews to speed up turnarounds on the ground, or to persevere with a landing when prudence would dictate a “go around”. In truth, if safety were an absolute priority, with no element of risk being tolerated, would planes ever take off? There is a popular internet meme, “we don’t make mistakes – we do variations”. It is particularly relevant to the safety critical community, who have picked up on it because it neatly encapsulates their thinking, e.g. this article by Steven Shorrock,
There is a popular internet meme, “we don’t make mistakes – we do variations”. It is particularly relevant to the safety critical community, who have picked up on it because it neatly encapsulates their thinking, e.g. this article by Steven Shorrock, 



 I want to take you back to the part of the world I come from, the east of Scotland. The Tay Bridge is 3.5 km long, the longest railway bridge in the United Kingdom. It’s the second railway bridge over the Tay. The first was opened in 1878 and came down in a storm in 1879, taking a train with it and killing everyone on board.
I want to take you back to the part of the world I come from, the east of Scotland. The Tay Bridge is 3.5 km long, the longest railway bridge in the United Kingdom. It’s the second railway bridge over the Tay. The first was opened in 1878 and came down in a storm in 1879, taking a train with it and killing everyone on board.
 The
The  The model explicitly states that taking out the unsafe act will stop an accident. It encouraged investigators to look for a single cause. That was immensely attractive because it kept attention away from any mistakes the management might have made in screwing up the organisation. The chain of collapsing dominos is broken by removing the unsafe act and you don’t get an accident.
The model explicitly states that taking out the unsafe act will stop an accident. It encouraged investigators to look for a single cause. That was immensely attractive because it kept attention away from any mistakes the management might have made in screwing up the organisation. The chain of collapsing dominos is broken by removing the unsafe act and you don’t get an accident. James Reason’s
James Reason’s 
 It was therefore a complete waste of time in a tightly time boxed audit if we waded through the specs. Context driven testers have been fascinated when I’ve explained that we started with a blank sheet of paper. The flows we were interested in were the things that mattered to the people that mattered.
It was therefore a complete waste of time in a tightly time boxed audit if we waded through the specs. Context driven testers have been fascinated when I’ve explained that we started with a blank sheet of paper. The flows we were interested in were the things that mattered to the people that mattered.
 We might have started with a blank sheet but we were highly rigorous. We used a structured methods modelling technique called IDEF0 to make sense of what we were learning, and to communicate that understanding back to the auditees to confirm that it made sense.
We might have started with a blank sheet but we were highly rigorous. We used a structured methods modelling technique called IDEF0 to make sense of what we were learning, and to communicate that understanding back to the auditees to confirm that it made sense.
 I investigated one careful user who stole over a million pounds, slice by slice, several thousand pounds a week, year after year, all without attracting any attention. He was exposed only by an anonymous tip off. It was always a real buzz working on those cases trying to work out exactly what the culprit had done and how they’d exploited the systems (note the plural – the best opportunities usually exploited loopholes between interfacing systems).
I investigated one careful user who stole over a million pounds, slice by slice, several thousand pounds a week, year after year, all without attracting any attention. He was exposed only by an anonymous tip off. It was always a real buzz working on those cases trying to work out exactly what the culprit had done and how they’d exploited the systems (note the plural – the best opportunities usually exploited loopholes between interfacing systems).



 At best we were running through a set of rituals to earn a fee that paid our salaries. The client got a clean, signed off set of accounts, but I struggled to see what value the information we produced might have for anyone. None of the methods we used seemed designed to tell us anything useful about what our clients were doing. It all felt like a charade. I was being told to do things and I just couldn’t see how anything made sense. I may as well have been trying to manage that flamingo, from Alice in Wonderland. That picture may seem a strange one to use, but it appeals to me; it sums up my confusion well. What on earth was the point of all these processes? They might as well have been flamingos for all the use they seemed. I hadn’t a clue.
At best we were running through a set of rituals to earn a fee that paid our salaries. The client got a clean, signed off set of accounts, but I struggled to see what value the information we produced might have for anyone. None of the methods we used seemed designed to tell us anything useful about what our clients were doing. It all felt like a charade. I was being told to do things and I just couldn’t see how anything made sense. I may as well have been trying to manage that flamingo, from Alice in Wonderland. That picture may seem a strange one to use, but it appeals to me; it sums up my confusion well. What on earth was the point of all these processes? They might as well have been flamingos for all the use they seemed. I hadn’t a clue.

