
Introduction
This is the ninth and final post in a series about problems that fascinate me, that I think are important and interesting. The series draws on important work from the fields of safety critical systems and from the study of complexity, specifically complex socio-technical systems. This was the theme of my keynote at EuroSTAR in The Hague (November 12th-15th 2018).
The first post was a reflection, based on personal experience, on the corporate preference for building bureaucracy rather than dealing with complex reality, “facing the dragons part 1 – corporate bureaucracies”. Part 2 was about the nature of complex systems. The third followed on from part 2, and talked about the impossibility of knowing exactly how complex socio-technical systems will behave with the result that it is impossible to specify them precisely, “I don’t know what’s going on”.
Part 4 “a brief history of accident models”, looked at accident models, i.e. the way that safety experts mentally frame accidents when they try to work out what caused them.
The fifth post, “accident investigations and treating people fairly”, looked at weaknesses in the way that we have traditionally investigated accidents and failures, assuming neat linearity with clear cause and effect. In particular, our use of root cause analysis, and willingness to blame people for accidents is hard to justify.
Part six “Safety II, a new way of looking at safety” looks at the response of the safety critical community to such problems and the necessary trade offs that a practical response requires. The result, Safety II, is intriguing and has important lessons for software testers.
The seventh post “Resilience requires people” is about the importance of system resilience and the vital role that people play in keeping systems going.
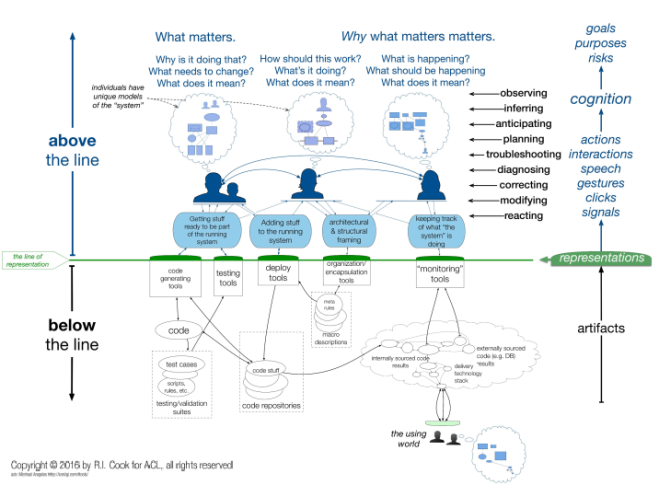
The eighth post “How we look at complex systems” is about the way we choose to look at complex systems, the mental models that we build to try and understand them, and the relevance of Devops.
This final post will try to draw all these strands together and present some thoughts about the future of testing as we are increasingly confronted with complex systems that are beyond our ability to comprehend.
Computing will become more complex
Even if we choose to focus on the simpler problems, rather than help users understand complexity, the reality is that computing is only going to get more complex. The problems that users of complex socio-technical systems have to grapple with will inevitably get more difficult and more intractable. The choice is whether we want to remain relevant, but uncomfortable, or go for comfortable bullshit that we feel we can handle. Remember Zadeh’s Law of Incompatibility (see part 7 – resilience requires people). “As complexity increases, precise statements lose their meaning, and meaningful statements lose precision”. Quantum computing, artificial intelligence and adaptive algorithms are just three of the areas of increasing importance whose inherent complexity will make it impossible for testers to offer opinions that are both precise and meaningful.
Quantum computing, in particular, is fascinating. By its very nature it is probabilistic, not deterministic. The idea that well designed and written programs should always produce the same output from the same data is relevant only to digital computers (and even then the maxim has to be heavily qualified in practice); it never holds true at any level for quantum computers. I wrote about this in “Quantum computing; a whole new field of bewilderment”.
The final quote from that article, “perplexity is the beginning of knowledge”, applies not only to quantum computing but also to artificial intelligence and the fiendish complexity of algorithms processing big data. One of the features of quantum computing is the way that changing a single qubit, the equivalent of digital bytes, will trigger changes in other qubits. This is entanglement, but the same word is now being used to describe the incomprehensible complexity of modern digital systems. Various writers have talked about this being the Age of Entanglement, eg Samuel Arbesman, in his book “Overcomplicated: Technology at the Limits of Comprehension)”, Emmet Connolly, in an article “Design in the Age of Entanglement” and Danny Hillis, in an article “The Enlightenment is Dead, Long Live the Entanglement”.
The purist in me disapproves of recycling a precise term from quantum science to describe loosely a phenomenon in digital computing. However, it does serve a useful role. It is a harsh and necessary reminder and warning that modern systems have developed beyond our ability to understand them. They are no more comprehensible than quantum systems, and as Richard Feynman is popularly, though possibly apocryphally, supposed to have said; “If you think you understand quantum physics, you don’t understand quantum physics.”
So the choice for testers will increasingly be to decide how we respond to Zadeh’s Law. Do we offer answers that are clear, accurate, precise and largely useless to the people who lose sleep at night worrying about risks? Or do we say “I don’t know for sure, and I can’t know, but this is what I’ve learned about the dangers lurking in the unknown, and what I’ve learned about how people will try to stay clear of these dangers, and how we can help them”?
If we go for the easy options and restrict our role to problems which allow definite answers then we will become irrelevant. We might survive as process drones, holders of a “bullshit job” that fits neatly into the corporate bureaucracy but offers little of value. That will be tempting in the short to medium term. Large organisations often value protocol and compliance more highly than they value technical expertise. That’s a tough problem to deal with. We have to confront that and communicate why that worldview isn’t just dated, it’s wrong. It’s not merely a matter of fashion.
If we’re not offering anything of real value then there are two possible dangers. We will be replaced by people prepared to do poor work cheaper; if you’re doing nothing useful then there is always someone who can undercut you. Or we will be increasingly replaced by automation because we have opted to stay rooted in the territory where machines can be more effective, or at least efficient.
If we fail to deal with complexity the danger is that mainstream testing will be restricted to “easy” jobs – the dull, boring jobs. When I moved into internal audit I learned to appreciate the significance of all the important systems being inter-related. It was where systems interfaced, and when people were involved that they got interesting. The finance systems with which I worked may have been almost entirely batch based, but they performed a valuable role for the people with whom we were constantly discussing the behaviour of these systems. Anything standalone was neither important nor particularly interesting. Anything that didn’t leave smart people scratching their heads and worrying was likely to be boring. Inter-connectedness and complexity will only increase and however difficult testing becomes it won’t be boring – so long as we are doing a useful job.
If we want to work with the important, interesting systems then we have to deal with complexity and the sort of problems the safety people have been wrestling with. There will always be a need for people to learn and inform others about complex systems. The American economist Tyler Cowen in his book “Average is Over” states the challenge clearly. We will need interpreters of complex systems.
“They will become clearing houses for and evaluators of the work of others… They will hone their skills of seeking out, absorbing and evaluating information… They will be translators of the truths coming out of our network of machines… At least for a while they will be the only people who will have a clear notion of what is going on.”
I’m not comfortable with the idea of truths coming out of machines, and we should resist the idea that we can ever be entirely clear about what is going on. But the need for experts who can interpret complex systems is clear. Society will look for them. Testers should aspire to be among those valuable specialists.  The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in part seven (Resilience requires people). Conductors are talented musicians in their own right, but they call on the expertise of different specialists, blending their contribution to produce something of value to the audience. Instead of a piece of music the interpreter tester would produce a story that sheds light on the system, guiding the people who need to know.
The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in part seven (Resilience requires people). Conductors are talented musicians in their own right, but they call on the expertise of different specialists, blending their contribution to produce something of value to the audience. Instead of a piece of music the interpreter tester would produce a story that sheds light on the system, guiding the people who need to know.
Testers in the future will have to be confident and assertive when they try to educate others about complexity, the inexplicable and the unknowable. Too often in corporate life a lack of certainty has been seen as a weakness. We have to stand our ground and insist on our right to be heard and taken seriously when we argue that certainty cannot be available if we want to talk about the risks and problems that matter. My training and background meant I couldn’t keep quiet when I saw problems, that were being ignored because no-one knew how to deal with them. As Better Software said about me, I’m never afraid to voice my opinion.
Never be afraid to speak out, to explain why your experience and expertise make your opinions valuable, however uncomfortable these may be for others. That’s what you’re paid for, not to provide comforting answers. The metaphor of facing the dragons of the unknown is extremely important. People will have to face these dragons. Testers have a responsibility to try and shed as much light as possible on those dragons lurking in the darkness beyond what we can see and understand easily. If we concentrate only on what we can know and say with certainty it means we walk away from offering valuable, heavily qualified advice about the risks, threats & opportunities that matter to people. Our job should entail trying to help and protect people. As Jerry Weinberg said in “Secrets of Consulting”;
“No matter what they tell you, it’s always a people problem.”


 The
The 