
")
 This article appeared in the June 2009 edition of Testing Experience magazine and the October 2009 edition of Security Acts magazine.
This article appeared in the June 2009 edition of Testing Experience magazine and the October 2009 edition of Security Acts magazine.
If you choose to read the article please bear in mind that it was written in January 2009 and is therefore inevitably dated in some respects. In particular, ISACA has restructured COBIT, but it remains a useful source. Overall I think the arguments I made in this article are still valid.
The references in the article were all structured for a paper magazine. They were not set up as hyperlinks and I have not tried to recreate them and check out whether they still work.
The article
When I started in IT in the 80s the company for which I worked had a closed network restricted to about 100 company locations with no external connections.
Security was divided neatly into physical security, concerned with the protection of the physical assets, and logical security, concerned with the protection of data and applications from abuse or loss.
When applications were built the focus of security was on internal application security. The arrangements for physical security were a given, and didn’t affect individual applications.
There were no outsiders to worry about who might gain access, and so long as the common access controls software was working there was no need for analysts or designers to worry about unauthorized internal access.
Security for the developers was therefore a matter of ensuring that the application reflected the rules of the business; rules such as segregation of responsibilities, appropriate authorization levels, dual authorization of high value payments, reconciliation of financial data.
The world quickly changed and relatively simple, private networks isolated from the rest of the world gave way to more open networks with multiple external connections and to web applications.
Security consequently acquired much greater focus. However, it began to seem increasingly detached from the work of developers. Security management and testing became specialisms in their own right, and not just an aspect of technical management and support.
We developers and testers continued to build our applications, comforted by the thought that the technical security experts were ensuring that the network perimeter was secure.photo of business logic security article header
Nominally security testing was a part of non-functional testing. In reality, it had become somewhat detached from conventional testing.
According to the glossary of the British Computer Society’s Special Interest Group in Software Testing (BCS SIGIST) [1], security testing is determining whether the application meets the specified security requirements.
SIGIST also says that security entails the preservation of confidentiality, integrity and availability of information. Availability means ensuring that authorized users have access to information and associated assets when required. Integrity means safeguarding the accuracy and completeness of information and processing methods. Confidentiality means ensuring that information is accessible only to those authorized to have access.
Penetration testing, and testing the security of the network and infrastructure, are all obviously important, but if you look at security in the round, bearing in mind wider definitions of security (such as SIGIST’s), then these activities can’t be the whole of security testing.
Some security testing has to consist of routine functional testing that is purely a matter of how the internals of the application work. Security testing that is considered and managed as an exercise external to the development, an exercise that follows the main testing, is necessarily limited. It cannot detect defects that are within the application rather than on the boundary.
Within the application, insecure design features or insecure coding might be detected without any deep understanding of the application’s business role. However, like any class of requirements, security requirements will vary from one application to another, depending on the job the application has to do.
If there are control failures that reflect poorly applied or misunderstood business logic, or business rules, then will we as functional testers detect that? Testers test at the boundaries. Usually we think in terms of boundary values for the data, the boundary of the application or the network boundary with the outside world.
Do we pay enough attention to the boundary of what is permissible user behavior? Do we worry enough about abuse by authorized users, employees or outsiders who have passed legitimately through the network and attempt to subvert the application, using it in ways never envisaged by the developers?
I suspect that we do not, and this must be a matter for concern. A Gartner report of 2005 [2] claimed that 75% of attacks are at the application level, not the network level. The types of threats listed in the report all arise from technical vulnerabilities, such as command injection and buffer overflows.
Such application layer vulnerabilities are obviously serious, and must be addressed. However, I suspect too much attention has been given to them at the expense of vulnerabilities arising from failure to implement business logic correctly.
This is my main concern in this article. Such failures can offer great scope for abuse and fraud. Security testing has to be about both the technology and the business.
Problem of fraud and insider abuse
It is difficult to come up with reliable figures about fraud because of its very nature. According to PriceWaterhouseCoopers in 2007 [3] the average loss to fraud by companies worldwide over the two years from 2005 was $2.4 million (their survey being biased towards larger companies). This is based on reported fraud, and PWC increased the figure to $3.2 million to allow for unreported frauds.
In addition to the direct costs there were average indirect costs in the form of management time of $550,000 and substantial unquantifiable costs in terms of damage to the brand, staff morale, reduced share prices and problems with regulators.
PWC stated that 76% of their respondents reported the involvement of an outside party, implying that 24% were purely internal. However, when companies were asked for details on one or two frauds, half of the perpetrators were internal and half external.
It would be interesting to know the relative proportions of frauds (by number and value) which exploited internal applications and customer facing web applications but I have not seen any statistics for these.
The U.S. Secret Service and CERT Coordination Center have produced an interesting series of reports on “illicit cyber activity”. In their 2004 report on crimes in the US banking and finance sector [4] they reported that in 70% of the cases the insiders had exploited weaknesses in applications, processes or procedures (such as authorized overrides). 78% of the time the perpetrators were authorized users with active accounts, and in 43% of cases they were using their own account and password.
The enduring problem with fraud statistics is that many frauds are not reported, and many more are not even detected. A successful fraud may run for many years without being detected, and may never be detected. A shrewd fraudster will not steal enough money in one go to draw attention to the loss.
I worked on the investigation of an internal fraud at a UK insurance company that had lasted 8 years, as far back as we were able to analyze the data and produce evidence for the police. The perpetrator had raised 555 fraudulent payments, all for less than £5,000 and had stolen £1.1 million pounds by the time that we received an anonymous tip off.
The control weaknesses related to an abuse of the authorization process, and a failure of the application to deal appropriately with third party claims payments, which were extremely vulnerable to fraud. These weaknesses would have been present in the original manual process, but the users and developers had not taken the opportunities that a new computer application had offered to introduce more sophisticated controls.
No-one had been negligent or even careless in the design of the application and the surrounding procedures. The trouble was that the requirements had focused on the positive functions of the application, and on replicating the functionality of the previous application, which in turn had been based on the original manual process. There had not been sufficient analysis of how the application could be exploited.
Problem of requirements and negative requirements
Earlier I was careful to talk about failure to implement business logic correctly, rather than implementing requirements. Business logic and requirements will not necessarily be the same.
The requirements are usually written as “the application must do” rather than “the application must not…”. Sometimes the “must not” is obvious to the business. It “goes without saying” – that dangerous phrase!
However, the developers often lack the deep understanding of business logic that users have, and they design and code only the “must do”, not even being aware of the implicit corollary, the “must not”.
As a computer auditor I reviewed a sales application which had a control to ensure that debts couldn’t be written off without review by a manager. At the end of each day a report was run to highlight debts that had been cleared without a payment being received. Any discrepancies were highlighted for management action.
I noticed that it was possible to overwrite the default of today’s date when clearing a debt. Inserting a date in the past meant that the money I’d written off wouldn’t appear on any control report. The report for that date had been run already.
When I mentioned this to the users and the teams who built and tested the application the initial reaction was “but you’re not supposed to do that”, and then they all tried blaming each other. There was a prolonged discussion about the nature of requirements.
The developers were adamant that they’d done nothing wrong because they’d built the application exactly as specified, and the users were responsible for the requirements.
The testers said they’d tested according to the requirements, and it wasn’t their fault.
The users were infuriated at the suggestion that they should have to specify every last little thing that should be obvious – obvious to them anyway.
The reason I was looking at the application, and looking for that particular problem, was because we knew that a close commercial rival had suffered a large fraud when a customer we had in common had bribed an employee of our rival to manipulate the sales control application. As it happened there was no evidence that the same had happened to us, but clearly we were vulnerable.
Testers should be aware of missing or unspoken requirements, implicit assumptions that have to be challenged and tested. Such assumptions and requirements are a particular problem with security requirements, which is why the simple SIGIST definition of security testing I gave above isn’t sufficient – security testing cannot be only about testing the formal security requirements.
However, testers, like developers, are working to tight schedules and budgets. We’re always up against the clock. Often there is barely enough time to carry out all the positive testing that is required, never mind thinking through all the negative testing that would be required to prove that missing or unspoken negative requirements have been met.
Fraudsters, on the other hand, have almost unlimited time to get to know the application and see where the weaknesses are. Dishonest users also have the motivation to work out the weaknesses. Even people who are usually honest can be tempted when they realize that there is scope for fraud.
If we don’t have enough time to do adequate negative testing to see what weaknesses could be exploited than at least we should be doing a quick informal evaluation of the financial sensitivity of the application and alerting management, and the internal computer auditors, that there is an element of unquantifiable risk. How comfortable are they with that?
If we can persuade project managers and users that we need enough time to test properly, then what can we do?
CobiT and OWASP
If there is time, there are various techniques that testers can adopt to try and detect potential weaknesses or which we can encourage the developers and users to follow to prevent such weaknesses.
I’d like to concentrate on the CobiT (Control Objectives for Information and related Technology) guidelines for developing and testing secure applications (CobiT 4.1 2007 [5]), and the CobiT IT Assurance Guide [6], and the OWASP (Open Web Application Security Project) Testing Guide [7].
Together, CobiT and OWASP cover the whole range of security testing. They can be used together, CobiT being more concerned with what applications do, and OWASP with how applications work.
They both give useful advice about the internal application controls and functionality that developers and users can follow. They can also be used to provide testers with guidance about test conditions. If the developers and users know that the testers will be consulting these guides then they have an incentive to ensure that the requirements and build reflect this advice.
CobiT implicitly assumes a traditional, big up-front design, Waterfall approach. Nevertheless, it’s still potentially useful for Agile practitioners, and it is possible to map from CobiT to Agile techniques, see Gupta [8].
The two most relevant parts are in the CobiT IT Assurance Guide [6]. This is organized into domains, the most directly relevant being “Acquire and Implement” the solution. This is really for auditors, guiding them through a traditional development, explaining the controls and checks they should be looking for at each stage.
It’s interesting as a source of ideas, and as an alternative way of looking at the development, but unless your organization has mandated the developers to follow CobiT there’s no point trying to graft this onto your project.
Of much greater interest are the six CobiT application controls. Whereas the domains are functionally separate and sequential activities, a life-cycle in effect, the application controls are statements of intent that apply to the business area and the application itself. They can be used at any stage of the development. They are;
AC1 Source Data Preparation and Authorization
AC2 Source Data Collection and Entry
AC3 Accuracy, Completeness and Authenticity Checks
AC4 Processing Integrity and Validity
AC5 Output Review, Reconciliation and Error Handling
AC6 Transaction Authentication and Integrity
Each of these controls has stated objectives, and tests that can be made against the requirements, the proposed design and then on the built application. Clearly these are generic statements potentially applicable to any application, but they can serve as a valuable prompt to testers who are willing to adapt them to their own application. They are also a useful introduction for testers to the wider field of business controls.
CobiT rather skates over the question of how the business requirements are defined, but these application controls can serve as a useful basis for validating the requirements.
Unfortunately the CobiT IT Assurance Guide can be downloaded for free only by members of ISACA (Information Systems Audit and Control Association) and costs $165 for non-members to buy. Try your friendly neighborhood Internal Audit department! If they don’t have a copy, well maybe they should.
If you are looking for a more constructive and proactive approach to the requirements then I recommend the Open Web Application Security Project (OWASP) Testing Guide [7]. This is an excellent, accessible document covering the whole range of application security, both technical vulnerabilities and business logic flaws.
It offers good, practical guidance to testers. It also offers a testing framework that is basic, and all the better for that, being simple and practical.
The OWASP testing framework demands early involvement of the testers, and runs from before the start of the project to reviews and testing of live applications.
Phase 1: Before Deployment begins
1A: Review policies and standards
1B: Develop measurement and metrics criteria (ensure traceability)
Phase 2: During definition and design
2A: Review security requirements
2B: Review design and architecture
2C: Create and review UML models
2D: Create and review threat models
Phase 3: During development
3A: Code walkthroughs
3B: Code reviews
Phase 4: During development
4A: Application penetration testing
4B: Configuration management testing
Phase 5: Maintenance and operations
5A: Conduct operational management reviews
5B: Conduct periodic health checks
5C: Ensure change verification
OWASP suggests four test techniques for security testing; manual inspections and reviews, code reviews, threat modeling and penetration testing. The manual inspections are reviews of design, processes, policies, documentation and even interviewing people; everything except the source code, which is covered by the code reviews.
A feature of OWASP I find particularly interesting is its fairly explicit admission that the security requirements may be missing or inadequate. This is unquestionably a realistic approach, but usually testing models blithely assume that the requirements need tweaking at most.
The response of OWASP is to carry out what looks rather like reverse engineering of the design into the requirements. After the design has been completed testers should perform UML modeling to derive use cases that “describe how the application works.
In some cases, these may already be available”. Obviously in many cases these will not be available, but the clear implication is that even if they are available they are unlikely to offer enough information to carry out threat modeling.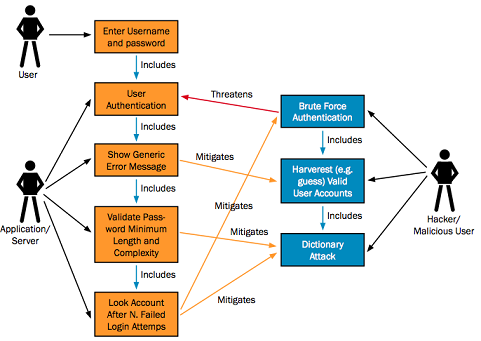
The feature most likely to be missing is the misuse case. These are the dark side of use cases! As envisaged by OWASP the misuse cases shadow the use cases, threatening them, then being mitigated by subsequent use cases.
The OWASP framework is not designed to be a checklist, to be followed blindly. The important point about using UML is that it permits the tester to decompose and understand the proposed application to the level of detail required for threat modeling, but also with the perspective that threat modeling requires; i.e. what can go wrong? what must we prevent? what could the bad guys get up to?
UML is simply a means to that end, and was probably chosen largely because that is what most developers are likely to be familiar with, and therefore UML diagrams are more likely to be available than other forms of documentation. There was certainly some debate in the OWASP community about what the best means of decomposition might be.
Personally, I have found IDEF0 a valuable means of decomposing applications while working as a computer auditor. Full details of this technique can be found at http://www.idef.com [9].
It entails decomposing an application using a hierarchical series of diagrams, each of which has between three and six functions. Each function has inputs, which are transformed into outputs, depending on controls and mechanisms.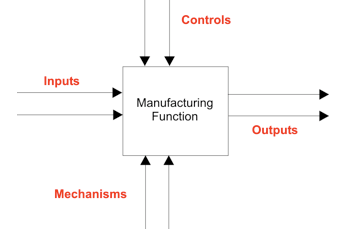
Is IDEF0 as rigorous and effective as UML? No, I wouldn’t argue that. When using IDEF0 we did not define the application in anything like the detail that UML would entail. Its value was in allowing us to develop a quick understanding of the crucial functions and issues, and then ask pertinent questions.
Given that certain inputs must be transformed into certain outputs, what are the controls and mechanisms required to ensure that the right outputs are produced?
In working out what the controls were, or ought to be, we’d run through the mantra that the output had to be accurate, complete, authorized, and timely. “Accurate” and “complete” are obvious. “Authorized” meant that the output must have been created or approved by people with the appropriate level of authority. “Timely” meant that the output must not only arrive in the right place, but at the right time. One could also use the six CobiT application controls as prompts.
In the example I gave above of the debt being written off I had worked down to the level of detail of “write off a debt” and looked at the controls required to produce the right output, “cancelled debts”. I focused on “authorized”, “complete” and “timely”.
Any sales operator could cancel a debt, but that raised the item for management review. That was fine. The problem was with “complete” and “timely”. All write-offs had to be collected for the control report, which was run daily. Was it possible to ensure some write-offs would not appear? Was it possible to over-key the default of the current date? It was possible. If I did so, would the write-off appear on another report? No. The control failure therefore meant that the control report could be easily bypassed.
The testing that I was carrying out had nothing to do with the original requirements. They were of interest, but not really relevant to what I was trying to do. I was trying to think like a dishonest employee, looking for a weakness I could exploit.
The decomposition of the application is the essential first step of threat modeling. Following that, one should analyze the assets for importance, explore possible vulnerabilities and threats, and create mitigation strategies.
I don’t want to discuss these in depth. There is plenty of material about threat modeling available. OWASP offers good guidance, [10] and [11]. Microsoft provides some useful advice [12], but its focus is on technical security, whereas OWASP looks at the business logic too. The OWASP testing guide [7] has a section devoted to business logic that serves as a useful introduction.
OWASP’s inclusion of mitigation strategies in the version of threat modeling that it advocates for testers is interesting. This is not normally a tester’s responsibility. However, considering such strategies is a useful way of planning the testing. What controls or protections should we be testing for? I think it also implicitly acknowledges that the requirements and design may well be flawed, and that threat modeling might not have been carried out in circumstances where it really should have been.
This perception is reinforced by OWASP’s advice that testers should ensure that threat models are created as early as possible in the project, and should then be revisited as the application evolves.
What I think is particularly valuable about the application control advice in CobIT and OWASP is that they help us to focus on security as an attribute that can, and must, be built into applications. Security testing then becomes a normal part of functional testing, as well as a specialist technical exercise. Testers must not regard security as an audit concern, with the testing being carried out by quasi-auditors, external to the development.
Getting the auditors on our side
I’ve had a fairly unusual career in that I’ve spent several years in each of software development, IT audit, IT security management, project management and test management. I think that gives me a good understanding of each of these roles, and a sympathetic understanding of the problems and pressures associated with them. It’s also taught me how they can work together constructively.
In most cases this is obvious, but the odd one out is the IT auditor. They have the reputation of being the hard-nosed suits from head office who come in to bayonet the wounded after a disaster! If that is what they do then they are being unprofessional and irresponsible. Good auditors should be pro-active and constructive. They will be happy to work with developers, users and testers to help them anticipate and prevent problems.
Auditors will not do your job for you, and they will rarely be able to give you all the answers. They usually have to spread themselves thinly across an organization, inevitably concentrating on the areas with problems and which pose the greatest risk.
They should not be dictating the controls, but good auditors can provide useful advice. They can act as a valuable sounding board, for bouncing ideas off. They can also be used as reinforcements if the testers are coming under irresponsible pressure to restrict the scope of security testing. Good auditors should be the friend of testers, not our enemy. At least you may be able to get access to some useful, but expensive, CobiT material.
Auditors can give you a different perspective and help you ask the right questions, and being able to ask the right questions is much more important than any particular tool or method for testers.
This article tells you something about CobiT and OWASP, and about possible new techniques for approaching testing of security. However, I think the most important lesson is that security testing cannot be a completely separate specialism, and that security testing must also include the exploration of the application’s functionality in a skeptical and inquisitive manner, asking the right questions.
Validating the security requirements is important, but so is exposing the unspoken requirements and disproving the invalid assumptions. It is about letting management see what the true state of the application is – just like the rest of testing.
References
[1] British Computer Society’s Special Interest Group in Software Testing (BCS SIGIST) Glossary.
[2] Gartner Inc. “Now Is the Time for Security at the Application Level” (NB PDF download), 2005.
[3] PriceWaterhouseCoopers. “Economic crime- people, culture and controls. The 4th biennial Global Economic Crime Survey”.
[4] US Secret Service. “Insider Threat Study: Illicit Cyber Activity in the Banking and Finance Sector”.
[5] IT Governance Institute. CobiT 4.1, 2007.
[6] IT Governance Institute. CobiT IT Assurance Guide (not free), 2007.
[7] Open Web Application Security Project. OWASP Testing Guide, V3.0, 2008.
[8] Gupta, S. “SOX Compliant Agile Processes”, Agile Alliance Conference, Agile 2008.
[9] IDEF0 Function Modeling Method.
[10] Open Web Application Security Project. OWASP Threat Modeling, 2007.
[11] Open Web Application Security Project. OWASP Code Review Guide “Application Threat Modeling”, 2009.
[12] Microsoft. “Improving Web Application Security: Threats and Countermeasures”, 2003.
")

 The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in
The complexity of these systems will be beyond the ability of any one person to comprehend, but perhaps these interpreters, in addition to deploying their own skills, will be able to act like a conductor of an orchestra, to return to the analogy I used in 

 Crucially, we must recognise that if we are attempting something new, that involves a significant amount of uncertainty then we start in the Complex domain exploring and discovering more about the problem. Once we have a better understanding and have found constraints that allow us to achieve repeatable outcomes we have moved the problem to the Complicated domain where we can manage it more easily and exploit our new knowledge. If our testing reveals that the constraints are not producing repeatable results then it’s important to get back into the Complex domain and carry out some more probing experiments.
Crucially, we must recognise that if we are attempting something new, that involves a significant amount of uncertainty then we start in the Complex domain exploring and discovering more about the problem. Once we have a better understanding and have found constraints that allow us to achieve repeatable outcomes we have moved the problem to the Complicated domain where we can manage it more easily and exploit our new knowledge. If our testing reveals that the constraints are not producing repeatable results then it’s important to get back into the Complex domain and carry out some more probing experiments.

 The
The 