
Introduction
This is the eighth post in a series about problems that fascinate me, that I think are important and interesting. The series draws on important work from the fields of safety critical systems and from the study of complexity, specifically complex socio-technical systems. This was the theme of my keynote at EuroSTAR in The Hague (November 12th-15th 2018).
The first post was a reflection, based on personal experience, on the corporate preference for building bureaucracy rather than dealing with complex reality, “facing the dragons part 1 – corporate bureaucracies”. Part 2 was about the nature of complex systems. The third followed on from part 2, and talked about the impossibility of knowing exactly how complex socio-technical systems will behave with the result that it is impossible to specify them precisely, “I don’t know what’s going on”.
Part 4 “a brief history of accident models”, looked at accident models, i.e. the way that safety experts mentally frame accidents when they try to work out what caused them.
The fifth post, “accident investigations and treating people fairly”, looked at weaknesses in the way that we have traditionally investigated accidents and failures, assuming neat linearity with clear cause and effect. In particular, our use of root cause analysis, and willingness to blame people for accidents is hard to justify.
Part six “Safety II, a new way of looking at safety” looks at the response of the safety critical community to such problems and the necessary trade offs that a practical response requires. The result, Safety II, is intriguing and has important lessons for software testers.
The seventh post “Resilience requires people” is about the importance of system resilience and the vital role that people play in keeping systems going.
This eighth post is about the way we choose to look at complex systems, the mental models that we build to try and understand them, and the relevance of Devops.
Choosing what we look at
The ideas I’ve been writing about resonated strongly with me when I first read about the safety and resilience engineering communities. What unites them is a serious, mature awareness of the importance of their work. Compared to these communities I sometimes feel as if normal software developers and testers are like children playing with cool toys while the safety critical engineers are the adults worrying about the real world.
The complex insurance finance systems I worked with were part of a wider system with correspondingly more baffling complexity. Remember the comments of Professor Michael McIntyre (in part six, “Safety II, a new way of looking at safety”).
“If we want to understand things in depth we usually need to think of them both as objects and as dynamic processes and see how it all fits together. Understanding means being able to see something from more than one viewpoint.”
If we zoom out for a wider perspective in both space and time we can see that objects which looked simple and static are part of a fluid, dynamic process. We can choose where we place the boundaries of the systems we want to learn about. We should make that decision based on where we can offer most value, not where the answers are easiest. We should not be restricting ourselves to problems that allow us to make definite, precise statements. We shouldn’t be looking only where the light is good, but also in the darkness. We should be peering out into the unknown where there may be dragons and dangers lurking.

Taking the wider perspective, the insurance finance systems for which I was responsible were essentially control mechanisms to allow statisticians to continually monitor and fine tune the rates, the price at which we sold insurance. They were continually searching for patterns, trying to understand how the different variables played off each other. We made constant small adjustments to keep the systems running effectively. We had to react to business problems that the systems revealed to our users, and to technical problems caused by all the upstream feeding applications. Nobody could predict the exact result of adjustments, but we learned to predict confidently the direction; good or bad.
The idea of testing these systems with a set of test cases, with precisely calculated expected results, was laughably naïve. These systems weren’t precise or accurate in a simple book-keeping sense, but they were extremely valuable. If we as developers and testers were to do a worthwhile job for our users we couldn’t restrict ourselves to focusing on whether the outputs from individual programs matched our expectations, which were no more likely to be “correct” (whatever that might mean in context) than the output.
Remember, these systems were performing massively complex calculations on huge volumes of data and thus producing answers that were not available any other way. We could predict how an individual record would be processed, but putting small numbers of records through the systems would tell us nothing worthwhile. Rounding errors would swamp any useful information. A change to a program that introduced a serious bug would probably produce a result that was indistinguishable from correct output with a small sample of data, but introduce serious and unacceptable error when we were dealing with the usual millions of records.
We couldn’t spot patterns from a hundred records using programs designed to tease out patterns from datasets with millions of records. We couldn’t specify expected outputs from systems that are intended to help us find out about unknown unknowns.
The only way to generate predictable output was to make unrealistic assumptions about the input data, to distort it so it would fit what we thought we knew. We might do that in unit testing but it was pointless in more rigorous later testing. We had to lift our eyes and understand the wider context, the commercial need to compete in the insurance marketplace with rates that were set with reasonable confidence in the accuracy of the pricing of the risks, rather than being set by guesswork, as had traditionally been the case. We were totally reliant on the expertise of our users, who in turn were totally reliant on our technical skills and experience.
I had one difficult, but enlightening, discussion with a very experienced and thoughtful user. I asked her to set acceptance criteria for a new system. She refused and continued to refuse even when I persisted. I eventually grasped why she wouldn’t set firm criteria. She couldn’t possibly articulate a full set of criteria. Inevitably she would only be able to state a small set of what might be relevant. It was misleading to think only in terms of a list of things that should be acceptable. She also had to think about the relationships between different factors. The permutations were endless, and spotting what might be wrong was a matter of experience and deep tacit knowledge.
This user was also concerned that setting a formal set of acceptance criteria would lead me and my team to focus on that list, which would mean treating the limited set of knowledge that was explicit as if it were the whole. We would be looking for confirmation of what we expected, rather than trying to help her shed light on the unknown.
Dealing with the wider context and becoming comfortable with the reality that we were dealing with the unknown was intellectually demanding and also rewarding. We had to work very closely with our users and we built strong, respectful and trusting relationships that ran deep and lasted long. When we hit serious problems, those good relations were vital. We could all work together, confident in each other’s abilities. These relationships have lasted many years, even though none of us still work for the same company.
We had to learn as much as possible from the users. This learning process was never ending. We were all learning, both users and developers, all the time. The more we learned about our systems the better we could understand the marketplace. The more we learned about how the business was working in the outside world the better our fine tuning of the systems.
Devops – a future reminiscent of my past?
With these complex insurance finance systems the need for constant learning dominated the whole development lifecyle to such an extent that we barely thought in terms of a testing phase. Some of our automated tests were built into the production system to monitor how it was running. We never talked of “testing in production”. That was a taboo phrase. Constant monitoring? Learning in production? These were far more diplomatic ways of putting it. However, the frontier between development and production was so blurred and arbitrary that we once, under extreme pressure of time, went to the lengths of using what were officially test runs to feed the annual high level business planning. This was possible only because of a degree of respect and trust between users, developers and operations staff that I’ve never seen before or since.
That close working relationship didn’t happen by chance. Our development team was pulled out of Information Services, the computing function, and assigned to the business, working side by side with the insurance statisticians. Our contact in operations wasn’t similarly seconded, but he was permanently available and was effectively part of the team.
The normal development standards and methods did not apply to our work. The company recognised that they were not appropriate and we were allowed to feel our way and come up with methods that would work for us. I wrote more about this a few years ago in “Adventures with Big Data”.
When Devops broke onto the scene I was fascinated. It is a response not only to the need for continuous delivery, but also to the problems posed by working with increasingly complex and intractable systems. I could identify with so much; the constant monitoring, learning about the system in production, breaking down traditional structures and barriers, different disciplines working more closely together. None of that seemed new to me. These had felt like a natural way to develop the deeply complicated insurance finance systems that would inevitably evolve into creatures as complex as the business environment in which they helped us to survive.
I’ve found Noah Sussman’s work very helpful. He has explicitly linked Devops with the ideas I have been discussing (in this whole series) that have emerged from the resilience engineering and safety critical communities. In particular, Sussman has picked up on an argument that Sidney Dekker has been making, notably in his book “Safety Differently”, that nobody can have a clear idea of how complex sociotechnical systems are working. There cannot be a single, definitive and authoritative (ie canonical) description of the system. The view that each expert has, as they try to make the system work, is valid but it is inevitably incomplete. Sussman put it as follows in his blog series “Software as Narrative”.
“At the heart of Devops is the admission that no single actor can ever obtain a ‘canonical view’ of an incident that took place during operations within an intractably complex sociotechnical system such as a software organization, hospital, airport or oil refinery (for instance).”
Dekker describes this as ontological relativism. The terminology from philosophy might seem intimidating, but anyone who has puzzled their way through a production problem in a complex system in the middle of the night should be able to identify with it. Brian Fay (in “Contemporary Philosophy of Social Science”) defines ontological relativism as meaning “reality itself is thought to be determined by the particular conceptual scheme of those living within it”.
If you’ve ever been alone in the deep of the night, trying to make sense of an intractable problem that has brought a complex system down, you’ll know what it feels like to be truly alone, to be dependent on your own skills and experience. The system documentation is of limited help. The insights of other people aren’t much use. They aren’t there, and the commentary they’ve offered in the past reflected their own understanding that they have constructed of how the system works. The reality that you have to deal with is what you are able to make sense of. What matters is your understanding, your own mental model.
I was introduced to this idea that we use mental models to help us gain traction with intractable systems by David Woods’ work. He (along with co-authors Paul Feltovich, Robert Hoffman and Axel Roesler) introduced me to the “envisaged worlds” that I mentioned in part one of this series. Woods expanded on this in “Behind Human Error” (chapter six), co-written with Sidney Dekker, Richard Cook, Leila Johannesen and Nadine Sarter.
These mental models are potentially dangerous, as I explained in part one. They are invariably oversimplified. They are partial, flawed and (to use the word favoured by Woods et al) they are “buggy”. But it is an oversimplification to dismiss them as useless because they are oversimplified; they are vitally important. We have to be aware of their limitations, and our own instinctive desire to make them too simple, but we need them to get anywhere when we work with complex systems.
Without these mental models we would be left bemused and helpless when confronted with deep complexity. Rather than thinking of these models as attempts to form precise representations of systems it is far more useful to treat them as heuristics, which are (as defined by James Bach, I think), a useful but fallible way to solve a problem or make a decision.
David Woods is a member of Snafucatchers, which describes itself as “a consortium of industry leaders and researchers united in the common cause of understanding and coping with the immense levels of complexity involved in the operation of critical digital services.”
Snafucatchers produced an important report in 2017, “STELLA – Report from the SNAFUcatchers Workshop on Coping With Complexity”. The workshop and report looked at how experts respond to anomalies and failures with complex systems. It’s well worth reading and reflecting on. The report discusses mental models and adds an interesting refinement, the line of representation.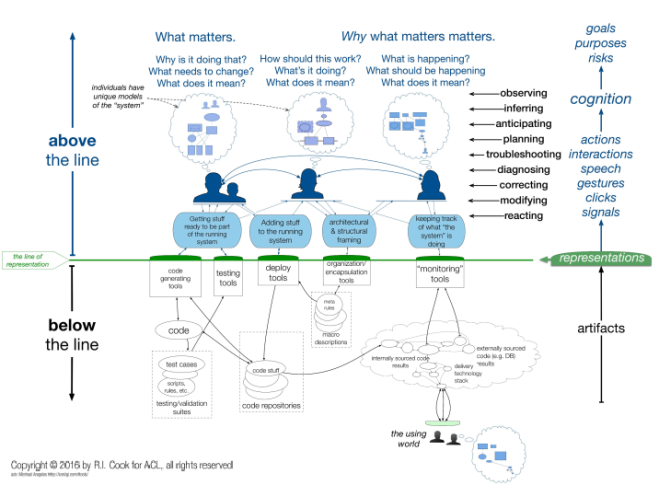
Above the line of representation we have the parts of the overall system that are visible; the people, their actions and interactions. The line itself has the facilities and tools that allow us to monitor and manage what is going on below the line. We build our mental models of how the system is working and use the information from the screens we see, and the controls available to us to operate the system. However, what we see and manipulate is not the system itself.
There is a mass of artifacts under the line that we can never directly see working. We see only the representation that is available to us at the level of the line. Everything else is out of sight and the representations that are available to us offer us only the chance to peer through a keyhole as we try to make sense of the system below. There has always been a large and invisible substructure in complex IT systems that was barely visible or understood. With internet systems this has grown enormously.
The green line is the line of representation. It is composed of terminal display screens, keyboards, mice, trackpads, and other interfaces. The software and hardware (collectively, the technical artifacts) running below the line cannot be seen or controlled directly. Instead, every interaction crossing the line is mediated by a representation. This is true as well for people in the using world who interact via representations on their computer screens and send keystrokes and mouse movements.
A somewhat startling consequence of this is that what is below the line is inferred from people’s mental models of The System.
And those models of the system are based on the partial representation that is visible to us above the line.
An important consequence of this is that people interacting with the system are critically dependent on their mental models of that system – models that are sure to be incomplete, buggy (see Woods et al above, “Behind Human Error”), and quickly become stale. When a technical system surprises us, it is most often because our mental models of that system are flawed.
This has important implications for teams working with complex systems. The system is constantly adapting and evolving. The mental models that people use must also constantly be revised and refined if they are to remain useful. Each of these individual models represents the reality that each operator understands. All the models are different, but all are equally valid, as ontological relativism tells us. As each team member has a different, valid model it is important that they work together closely, sharing their models so they can co-operate effectively.
This is a world in which traditional corporate bureaucracy with clear, fixed lines of command and control, with detailed and prescriptive processes, is redundant. It offers little of value – only an illusion of control for those at the top, and it hinders the people who are doing the most valuable work (see “part 1 – corporate bureaucracies”).
For those who work with complex, sociotechnical systems the flexibility, the co-operative teamwork, the swifter movement and, above all, the realism of Devops offer greater promise. My experience with deeply complex systems has persuaded me that such an approach is worthwhile. But just as these complex systems will constantly change so must the way we respond. There is no magic, definitive solution that will always work for us. We will always have to adapt, to learn and change if we are to remain relevant.
It is important that developers and testers pay close attention to the work of people like the Snafucatchers. They are offering the insights, the evidence and the arguments that will help us to adapt in a world that will never stop adapting.
In the final part of this series, part 9 “Learning to live with the unknowable” I will try to draw all these strands together and present some thoughts about the future of testing as we are increasingly confronted with complex systems that are beyond our ability to comprehend.
